综合评价工作在社会各领域应用普遍,是科学合理做出管理决策的重要依据。随着各界研究领域的不断扩大,面对的评价目标及其对象日趋复杂,当针对某一评价目标围绕某些对象进行评价时,如果仅从单一指标出发进行考量,会显得不是很全面也不科学。比如企业员工评级,除了岗位绩效,也要综合员工品行、个人技能、工作主动性、与同事之间的协调合作能力等等因素。因此,通常情况下,对象/问题评价往往需要设计多个维度、多个层次的指标,进行多指标综合评价,从而得到更加全面科学的结论,以辅助管理决策。
目前,围绕评价目的、指标体系的构建、指标权重的确定、数据来源与处理、评价信息的集成和结果的分析应用等方面,国内外已经形成了较为系统成熟的理论和方法体系,本文特对有关综合评价的基础理论和方法进行如下梳理总结,以供相关研究参考。
1.简述
关于综合评价(Comprehensive Evaluation,CE)的定义,一般是指基于评价目的,确定评价对象,通过全面测定或衡量评价对象的特征属性,采用合理的评价方法/模型融合多个属性特征信息,来综合反映研究对象总体特征,以供横向或纵向比较等应用。[1][2]
1.1 综合评价的主要目标
进行综合评价分析,必须先明确其评价目标,通常情况下,综合评价目标可大概分为以下几类:
其一,分类问题,对所研究对象的全部单位进行分类;
其二,比较排序问题,比较所研究对象的全部单位、进行综合排序,或在分类基础上对各小类单位评估优劣进行排序;
其三,某一综合目标的整体实现程度评价(对某一事物作出整体评价)问题,如小康目标的实现程度、社会现代化实现程度,当然必须有参考系。
1.2 综合评价的构成要素
能形成综合评价问题的主要构成要素包括:评价对象、评价指标、权重系数、综合评价模型和评价者。
(1)评价对象
评价对象是综合评价问题中的研究对象,或称为系统。一般而言,针对综合评价目的,评价对象是属于同一类的,且个数要大于1。
(2)评价指标
评价指标是用来测度评价对象(或系统)运行(或发展)状况的基本要素。通常情况下,综合评价问题是由多项评价指标构成的指标体系来衡量,体系中的各项指标从不同维度度量评价对象的关键特征。
(3)权重系数
每一综合评价问题都有相应的评价目的,评价目的的不同往往各评价指标之间的相对重要程度是不同的,评价指标之间这种相对重要程度的大小就是用指标权重系数来表示。
(4)综合评价算法/模型
针对多指标(或多因素)的综合评价问题,基于评价指标体系的构建、权重系统的分配之后,需要设计合适的综合评价算法或建立科学的综合评价模型,将多个评价指标综合成一个评价值,作为综合分析的依据,从而得到相应的评价结果。
(5)评价者
评价者是针对评价目标,直接进行综合评价的参与人,可以是某个人,也可以是某一个团队。对于评价目标的确定、指标体系的构建、权重系数的计算、评价算法/模型的建立,都由评价者决定。
1.3 综合评价的一般流程
基于国内外相关研究,结合以往分析实践经验来看,综合评价问题研究的主要流程包括:
(1)确定综合评价的目标:如上文所述的主要几类目标,明确实际问题的评价目的;
(2)构建评价指标体系:基于评价目的,针对评价对象,参考相关研究文献,并遵循指标体系构建的目标性、系统全面性、科学合理性、可比可操作性等原则,构建评价指标体系,一般包括定性分析法和定量分析法;其中,常用的定性分析方法有(专家)综合法和因素分析法,定量分析方法有系统聚类、极大不相关法、条件广义方差极小法、选取典型指标法以及试算法等;
(3)指标数据的获取与处理:按评价指标体系,全面搜集各渠道数据,依次提取指标数据,并进行指标数据预处理,指标数据预处理通常包括指标同向化、无量纲化两个主要处理步骤,相关方法较多,特在下文进行详细介绍;
(4)评价指标权重的确定:在对综合评价问题进行实际测算时,当评价对象、评价指标及其数值确定以后,指标权重系数合理与否直接关系到综合评价结果的可信度,甚至影响到最终决策的优劣,因此,下文会对权重系数的计算方法进行详细介绍;
(5)综合评价算法设计/模型构建:基于指标数值、指标权重系数,需设计合适的综合评价算法/构建合适的综合评价模型,下文对经典的综合评价算法/模型进行了详细介绍,可结合实际情况进行相应的改进;
(6)综合评价结果的分析及应用:基于综合评价结果,围绕评价目标开展多维度的分析及应用。
2. 评价指标数据预处理
评价指标数据的预处理操作一般包括指标属性同向化处理和数据无量纲化处理,其中,指标同向化处理(若一些指标的数据越大越好,另一些指标的数据越小越好,会造成尺度混乱),是使所有指标都是从同一方向评价总体;指标无量纲化处理,是为消除指标之间不同计量单位(不同度量)对指标数值大小的影响和指标数值不能对比综合而进行的一种预处理方式。这两种预处理方法通常包括:(数据冗余、异常值及缺失值等数据处理方法在此不展开,如有需要可根据实际情况进行相应处理。)
2.1 评价指标属性同向化
据以往经验总结,评价指标属性可能为“极大型”、“极小型”、“中间型”或“区间型”,其中,极大型指标又称正向指标,通常指与评价目标呈正相关关系的指标,期望指标的取值越大越好。针对各属性指标,为了可以进行综合评价,需要解决同方向性,往往需要将其他类型的指标进行正向化处理,使其和极大型指标一样和评价目标同向化变动。
(1)极小型指标:又称逆向指标,通常与评价目标呈负相关关系,期望指标的取值越小越好,其处理方法包括:

(2)中间型指标:期望指标的取值既不要太大,也不要太小,即取适当的中间值为最好,其处理方式为:

(3)区间型指标:期望指标的取值最好是落在某一个确定的区间内为最好,其处理方式为:
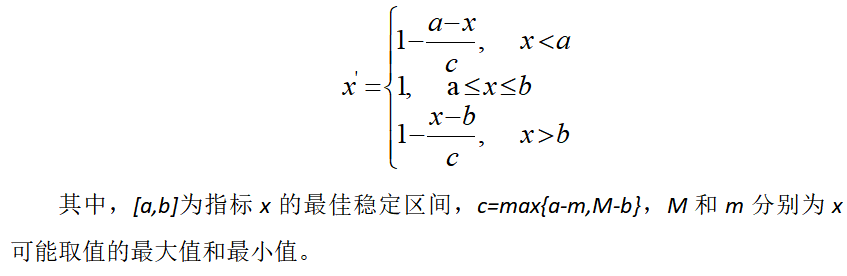
2.2 评价指标数值无量纲化
通常情况下,由于各评价指标性质不同,而具有不同量纲和数量级。当各指标间的数值水平相差很大时,指标之间往往不能直接进行数值比较和综合评价,若用原始数值进行分析,就会突出数值较大的指标在综合评价中的作用,相对削弱数值水平较低指标的作用,则可能出现“大数吃小数”情况,导致错误的评价结果。因此,为保证结果的可靠性,一般需要对评价指标原始数值进行无量纲化处理,无量纲化处理又称指标数据的标准化、归一化或规范化处理,常用的方法包括:(以下公式是,假定针对有n个评价对象、m个评价指标的综合评价体系,对于第i个对象的第j个指标数值的处理。)
(1)Min-Max标准化
也叫离差标准化、极值差法,通过对原始数据进行线性变换,使其映射在[0,1]区间,转换函数如下:

Min-Max标准化方法处理简单易理解,且不改变指标原始数据分布,适用于指标数据的最大值和最小值是明确不变的情况,若最大最小值易变,则会导致后续测算的结果不稳定,实际应用中往往用常量来代替。
(2)Z-Score标准化
Z-Score标准化也称标准差标准化,是基于指标原始数据的均值和标准差进行数据标准化处理的方法,是SPSS统计软件中默认的标准化方法。这种方法会改变指标原始数据分布,对离群点的规范化效果好,适用于指标数值最大值和最小值未知的情况,或原始数据接近正态分布的情况,或有超过取值范围的离群数据的情况。
处理后的数据符合标准正态分布,即均值为0,标准差为1,其转化函数为:
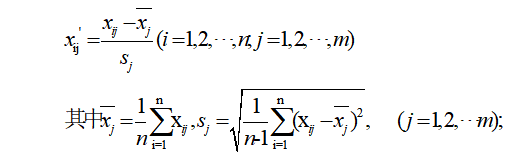
(3)归一化方法
指标数据归一化至(0,1]区间,得到的指标归一化值求和为1,常见的处理方式为:
A.数值归一化
若指标数值全是正数,只想直接对数值归一化至(0,1]区间,可通过指标原始数据中的每个值除以指标数据之和进行标准化,公式为:

B.排序归一化
若并不关注指标数值归一化的具体值,更关注指标数值的相对排序,可采用指标排序归一化处理方式,公式为:
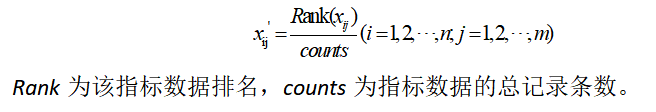
C.分段归一化
这种方法是较为复杂的归一化处理方式,但更能贴近业务、能整合多个方法的优点,适用于数据分布有明显分段特征的指标,处理方法为:先根据业务经验对数据分段,在不同分段内使用相应方法。
(4)指数转换
通过对指标原始数据进行相应的指数函数变换来进行数据的标准化,常见的处理方法为:
A.log函数转换
又称对数标准化,通过以10为底的log函数转换的方法进行数据标准化,较多处理公式是:x=log10(x),但这处理后的结果并非一定落在(0,1]区间,要使处理后的数值落到此区间,处理公式为:ln(指标原数据)/ln(指标数据最大值)
这种处理方法适用于长尾分布的原始数据,需要对样本做分段操作的情况。
B.atan函数转换
用反正切函数也可以实现数据的归一化,使用这个方法需要注意的是如果想映射的区间为[0,1],则数据都应该大于等于0,小于0的数据将被映射到[-1,0]区间上。
C.softmax函数转换
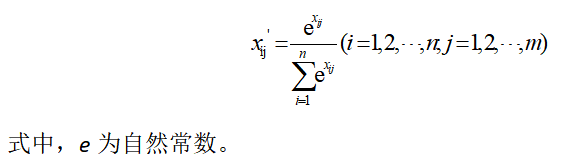
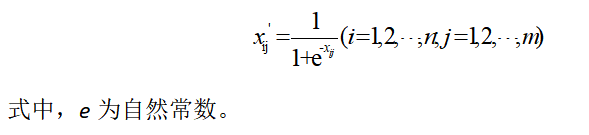
(5)小数定标标准化
小数定标标准化是指,通过移动原始数据小数点的位置来进行标准化。小数点移动的位数取决于原始数据中的最大绝对值。计算公式为:

3. 评价指标权重计算
在综合评价体系中,指标权重系数的确定是非常关键的环节,诸多学者就此方向展开了广泛研究。通过相关文献梳理,下文将指标权重确定的经典方法总结如下。在实际测算分析中 ,可综合研究目标、数据特征以及专业知识选择相应的权重计算方法。

3.1 主观赋权法
主观赋权法是指评价者基于评价目,通过哲学思辨、逻辑分析和经验判断,对评价对象的特征信息进行综合分析,从而得到指标权重的方法。常用的主观赋权方法有专家会议法、直接评分法、德尔菲法、层次分析法等。主观赋权的方法能充分利用评价者(专家)的专业知识、经验或价值判断,在战略决策类问题、或难以量化的评价系统、或评价精度要求不是很高的综合评价系统中应用普遍。本文对这类方法中的经典方法具体介绍如下:
层次分析法(Analytic Hierarchy Process,简称“AHP”)是美国运筹学家Saaty等人在20世纪70年代提出的一种综合定性与定量的决策分析法,针对评价对象分解成目标、准则、方案等层次,通过判断各层次指标的相对重要程度,综合评价者的主观判断和客观推理,从而计算得到决策方案中每个评价指标的权重,在一定程度避免了单纯因为主观经验造成的逻辑错误等问题,是应用较为普遍的一种基于经验定权方法。此方法的主要计算步骤为:(注意:AHP计算中提到的特征向量、特征值并不是矩阵中的概念,是重新定义的。)[3][4]
(1)构建梯阶层次结构模型
采用AHP进行综合评价问题分析时,首先需构建一个有层次的结构模型,这些层次一般可分为:最高层(目标层)、中间层(准则层)、最底层(方案层),梯阶层次结构中的层次数与问题复杂程度有关,层次数通常不受限制;
(2)构造各层次指标的两两比较判断矩阵
针对评价目标设计的准则层及方案层等各层次指标,在综合评价时所占比重往往不同,因此,可先通过评价者对各层次指标进行相对重要程度的判别,从而构建各层次指标的判断矩阵,一般判断矩阵的构建常引用数字1-9及其倒数作为标度,整理相关文献对判断矩阵标度的定义如表1所示。


(3)计算判断矩阵的特征向量、指标权重向量和特征值
对判断矩阵各列进行归一化,即每个元素都除以当前列元素之和,公式为:

(4)判断矩阵的一致性检验

3.2 客观赋权法
由于主观赋权法较为依赖评价者的专业知识和经验判断能力,常使评价结果波动性较大、可比性较差,因此,基于指标数据进行更为科学合理的客观赋权法应运而生。客观赋权法是评价者基于评价目的构建的综合评价体系,抛开经验判断,主要充分利用评价对象属性及其数据信息,对评价指标进行权重系数计算的方法。这类方法在综合评价问题中应用相对较为广泛,包括熵权法、变异系数法、灰色关联度分析法、神经网络分析法等,本文具体介绍如下方法:
3.2.1 熵权法
熵权法(the Entropy Weight Method,简称“EWM”)是基于信息论的基本原理,利用各指标熵值所反映的信息量大小来计算指标权重的一种客观赋权方法。[5]此方法的主要计算步骤为:
(1)对原始数据矩阵进行归一化处理
熵权法计算评价指标权重,只需要对指标原始数据进行归一化处理,不需要进行同向化处理(同向化会损失原始数据信息,不利于信息熵计算),归一化处理方法按需选用上文介绍的其中一种方法即可,下方为一般方法:

(2)各指标熵值计算

(3)各指标熵权系数计算

3.2.2 变异系数法
变异系数法(Coefficient of Variation Method)是一种基于统计学方法计算各评价指标变化程度的客观赋权法,不需要依靠专家经验,而是直接利用各指标数据信息计算得到各指标的权重系数。这一方法的基本假设是:在综合评价体系中,变化差异越大的指标越重要,因为它更能反映出参加评价的各对象之间的差距,所以其权重系数应越大。该方法通过计算变异系数来衡量各项评价指标取值的差异程度,从而计算其权重系数。[2]

3.2.3 灰色关联度分析法
灰色关联度分析(Grey Relational Analysis,简称“GRA”)是一种利用灰色系统理论进行多因素统计分析的方法,主要方式是关联分析,分析各个因素对结果的影响程度,计算其关联程度,从而决定重要因素,一般适用于评价信息少、数据不明确的综合评价问题。[6]采用GRA方法进行综合评价的主要计算步骤为:
(1)对原始数据集中进行指标属性同向化处理、无量纲化处理
评价指标同向化及无量纲化处理方法按需选用一种上文介绍的方法即可,将评价指标原始数据矩阵依次进行同向化、无量纲化处理后,得到标准化矩阵Z:
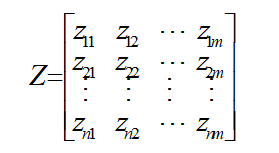
(2)确定母序列、子序列

(3)计算各指标子序列元素与母序列对应元素间的灰色关联度

(4)计算各评价指标的权重

4.综合评价方法/模型选择
确定指标权重系数之后,就是选取合适的综合评价方法/模型进行测算和分析了,下文同样详细介绍几种经典的算法/模型,其他方法因篇幅有限,本文不做详细介绍,可按需参考相关文献选择或改进相应方法即可。

4.1 优劣解距离法
优劣解距离法(Technique for Order Preference by Similarity to an Ideal Solution,简称“TOPSIS”)是一种应用较为普遍的综合评价方法,该方法对指标原始数据分布及样本量没有严格限制,方法简单易行的同时,能充分利用原始数据的信息,其结果能精确反映各评价方案之间的差距。[7][8][9][10]此方法的主要计算步骤为:
(1)对原始数据集中进行指标属性同向化处理、无量纲化处理
评价指标同向化及无量纲化处理方法按需选用一种上文介绍的方法即可,将评价指标原始数据矩阵依次进行同向化、无量纲化处理后,得到标准化矩阵Z:

(2)确定最优值向量Z+和最劣值向量Z-

(3)计算各评价对象属性值与最优值、最劣值的距离

(4)计算各评价对象属性与最优值向量的相对接近度

(5)按照Ci大小进行排序,即可给出综合评价结果,进行综合分析。
4.2 秩和比法
由上文可支,TOPSIS算法简单易操作,能充分利用原始数据信息,但由于它完全依赖现有数值情况,不适用模糊性指标的处理,而秩和比法(Rank-Sum Ratio,简称“RSR”)恰好弥补了它的不足。RSR法由我国著名卫生统计学家田风调先生创立,是一种综合古典参数统计和近代非参数统计各自优点于一体的一种统计分析方法,适用于各种评价对象,对评价指标的选择无特殊要求,且计算时利用的是秩次信息,可以消除异常数值的干扰。[11]采用RSR方法进行综合评价的主要计算步骤为:
(1)对原始数据表进行编秩
对n个评价对象m个评价指标排列成的n行m列原始数据表,按每个评价指标分别对各评价对象进行编秩,通常情况下编秩方法一般包括两种,可根据实际情况选一种即可,得到秩矩阵,记为R=(Rij)n×m:
A.整次秩和比法
按各评价对象指标的原始数据,对每个指标中各评价对象的属性值进行排序编秩,其中,极大型指标从小到大编秩(值越大,秩数值越大),极小型指标从大到小编秩(值越小,秩数值越大),同一指标数据相同者编平均秩。如某极大型指标各评价对象属性值分别为20,5,9,10,则秩数值可分别为4,1,2,3。
B非整次秩和比法
为改进整次秩和比法中易损失指标原始数值定量信息的缺点,非整次秩和比法采用类似线性插值的方式,对指标原始数值进行编秩,使得所编秩次与原始数值之间存在线性对应关系,减少定量信息的缺失,计算公式如下:(注:线性模型可基于实际情况进行扩展,如指数、对数等其他方法。)
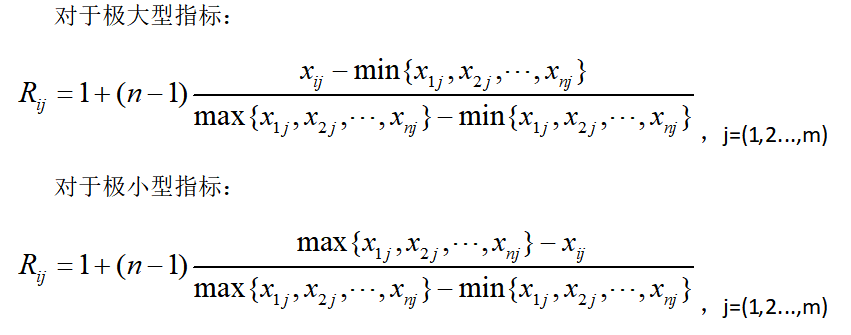
(2)计算秩和比并排序

如果只考虑评价对象的排序问题、不考虑具体值的话,此时,已基本完成了综合评价的基本分析,但如果希望从正态分布角度对数据进行分层,完成更为具体的分析,请查阅参考文献[11]。
4.3 模糊综合评价法
模糊综合评价法(Fuzzy Comprehensive Evaluation,简称“FCE”)基于模糊数学理论,通过将边界不清、不易定量的评价指标因素定量化,从而进行综合评判。FCE法适用于指标较少的综合评价问题,主要计算步骤为:[12]
(1)构建评价对象的因素集
因素(指标)集是指对评价对象进行综合评价的各因素指标构成的集合,通常用U表示,U=(u1,u2,...,um),其中ui表示影响评价对象的第i个评价指标,这些因素一般具有不同程度的模糊性。
(2)构建综合评价的评价集
评价集是指将评价者对评价对象可能打出的各种结果所构成的集合,通常用V表示,V=(v1,v2,..,vn),其中vj表示对某个评价指标的第j种评价等级,一般可分为五个等级:V={优,良,中等,较差,差}。
(3)进行单因素模糊评价,获得评价矩阵
如果在因素集U中第i个因素的评价集V中,其第1个元素的隶属度为ri1,则对第i个元素进行单因素评价的结果可以用模糊集合表示为:Ri=(ri1,ri2,...,rin),以m个单因素评价集R1,R2,...,Rm为行组成矩阵Rm×n,称为模糊综合评价矩阵。
(4)构建综合评价模型
基于上文所述的权重系数计算方法,按需选取计算得到各评价指标的权重集,用A表示:A=(a1,a2,...,am);基于单因素判断矩阵R和因素权重向量A,通过模糊变化将U上的模糊向量A变为V上的模糊向量B,即B=A1*m⭕Rm*n=(b1,b2,...,bn),其中⭕为综合评价合成算子,一般取矩阵乘法即可。
(5)计算系统总得分
构建综合评价模型之后,即可计算系统总得分,即F=B1*n*ST1*n,其中F为系统总得分,S为V中相应因素的级分。(详细示例参考:参考:https://zhuanlan.zhihu.com/p/32666445)
4.4 主成分分析法
在诸多综合评价的实际问题中,往往涉及多个变量,而且不同指标之间具有一定相关性,这无疑增加了问题分析的复杂性。此时,若盲目地减少评价指标,则会损失很多重要特征,可能导致错误的评价结果;若分别分析各评价指标,结果又过于独立,并没有对评价对象进行综合评价。因此,需要从大量原始指标中提取少许综合评价指标,使其大体上反映评价对象全部指标的变化,而不丧失或只丧失很小一部分原始指标所提供的信息,这种将多个指标组合成少许相互无关的综合指标的统计方法叫主成分分析(Principal Components Analysis,简称“PCA”)。
PCA通过分析原始评价指标相关矩阵或协方差矩阵的内部结构关系,对原始变量进行线性组合形成几个主成分,使得在保留原始变量主要信息的前提下起到评价指标降维与问题简化的作用。其基本原理为:(如下步骤主要介绍基本思想,未展开介绍,具体可见参考文献。)[13]



一般而言,采用PCA得到的主成分指标与原始评价指标之间存在如下基本关系:
每一个主成分都是各原始评价指标的线性组合;
主成分保留了原始评价指标的绝大部分信息;
主成分的数量大大少于原始评价指标的数量;
主成分之间互不相关。
4.5 因子分析法
因子分析法(Factor Analysis)是主成分分析的推广,也是采用降维思想,基于原始评价指标相关矩阵内部的依赖关系,把一些具有错综复杂关系的变量组合成少数几个综合因子的一种多变量统计分析方法。相比主成分分析,因子分析更倾向于描述原始变量之间的相关关系,其基本思想是利用原始变量的相关矩阵,根据相关性大小将原始变量分组,使得同组变量之间相关性较高,而不同组之间的相关性较低。基本步骤如下:(如下步骤主要介绍基本思想,未展开介绍,具体可见参考文献。)[13]
(1)基于研究目标选取原始评价指标,分析并确认是否适合做因子分析;
(2)将原始评价指标数据进行标准化,以消除变量之间属性和量纲之间的差异性;
(3)计算标准化数据的相关矩阵,分析变量之间的相关性;
(4)计算初始公因子及因子载荷矩阵。通过分析原始变量之间的相关性,基于研究目标提取主要公因子,提取方法是利用因子载荷矩阵,求解因子载荷矩阵的方法主要有主成分分析法、主轴因子法、极大似然法等;
(5)因子旋转。若旋转前的公因子具有可解释性,则可跳过这一步;反之,则需要通过因子旋转,使得公因子具有可解释性;
(6)利用原始变量之间的线性组合,计算因子得分;
(7)综合得分。基于因子得分,以各因子的方差贡献率为权重,计算综合评价函数,综合评价模型为:

(8)利用综合得分对评价对象进行比较分析。
综上,因子分析和主成分分析都是利用降维思想的一种多元统计分析方法,两者既有联系又有区别:
(1)因子分析是从数据中探查能对变量起解释作用的公因子和特殊因子,以及公因子和特殊因子组合系数;而主成分只是从空间生成的角度寻找能解释多变量变异绝大部分的几组彼此不相关的新变量(主成分);
(2)因子分析是把变量表示成各因子的线性组合,而主成分分析中则把主成分表示各变量的线性组合;
(3)因子分析需要一些假设,而主成分分析不需要假设。因子分析的假设包括:各公共因子之间不相关,特殊因子之间不相关,公共因子和特殊因子之间也不相关;
(4)因子分析抽取主因子的方法不仅有主成分分析法,还有极大似然法等;而主成分只能用主成分法抽取;
(5)因子分析法中因子不是固定的,可以旋转得到不同的因子;而主成分分析中,当给定的协方差矩阵或者相关矩阵的特征值是唯一的,主成分一般是固定的;
(6)在因子分析中,因子个数需要评价者指定,因子数不同、评价结果不同;而主成分分析中,成分个数是一定的,一般有几个变量就有几个主成分。
4.6 其他简易综合评价模型
除了上述经典的综合评价方法,可综合评价指标权重信息和数据信息,对评价对象进行分析,此外,通过选择合适的数学关系构造综合评价函数(即综合评价模型),也是应用较为普遍的方法,下文主要介绍线性加权和非线性加权这两种常用的模型,其他如代换模型、加乘混合模型等,本文不做具体介绍。
(1)线性加权综合模型
是指利用线性加权函数作为综合评价模型,分别对n个评价对象进行综合评价。公式为:

线性加权综合法具有如下特点:
适用于各评价指标之间相互独立的情况,对于评价指标之间不完全独立的情况,综合评价结果可能存在评价指标间信息重复的问题、不能客观反映实际水平;
该方法可使各评价指标间得到线性补偿,保证综合评价结果的公平性;
该方法中评价指标的权重系数作用明显,即权重较大的评价指标对综合评价结果影响更明显;由于各评价指标数值之间可以线性补偿,因此,当权重系数预先指定时,该方法对区分各备选方案之间的差异表现不敏感;
该方法对于(无量纲)指标数据没有特定要求;
该方法计算简单、可操作性强,应用普遍。
(2)非线性加权综合模型
非线性加权综合法又称“乘法合成法”或“加权几何算子”,是指利用非线性加权函数作为综合评价模型,分别对n个评价对象进行综合评价的一种方法。公式为:

非线性加权综合法具有如下特点:
适用于各评价指标之间有较强关联的情况;
该方法对评价指标数据要求较高,指标预处理后的数值要求大于或等于1;
该方法强调的是各备选方案(无量纲)指标值大小的一致性;
同线性加权综合法相比,该方法计算较为复杂,各评价指标权重系数对综合评价结果产生的作用没那么明显,此外,该方法对评价指标数值变动的反映比线性加权综合法更为敏感。
5.总结
国内外有关综合评价体系的理论与方法诸多,本文已将经典常用的方法进行了详细梳理,足够支持解决大部分的综合评价问题。鉴于所选择的方法不同,形成的综合评价结果往往不同,因此,在实际进行综合评价分析时,应基于评价目标,结合评价对象本身属性特征的分析,并遵循科学合理性、可操作性、可比性和有效性等原则,选择构建合适的综合评价算法/模型,以得到客观的综合评价分析结果,从而辅助决策。
综合评价体系理论和方法的未来发展趋势主要包括三点:
(1)综合评价体系逐渐从个体评价发展为群体评价、从单目标评价发展为多目标评价、从静态评价发展为动态评价、从单一评价发展为组合评价、从结果评价发展为过程评价等;
(2)基于互联网与大数据等新兴信息技术进行创新优化,综合评价流程和方法更加智能化;
(3)综合评价数据质量和规模大幅度提升,算法和模型设计需求逐渐复杂,评价结果更加科学全面。
参考文献
[1]彭张林,张强,杨善林.综合评价理论与方法研究综述[J].中国管理科学,2015,23(S1):245-256.
[2]曾五一, 肖红叶. 统计学导论(第二版)[M]. 科学出版社, 2013.
[3]Saaty T.L.,Vargas L.G.. Estimating technological coefficients by the analytic hierarchy process[J]. Pergamon,1979,13(6).
[4]邓雪,李家铭,曾浩健,陈俊羊,赵俊峰.层次分析法权重计算方法分析及其应用研究[J].数学的实践与认识,2012,42(07):93-100.
[5]章穗,张梅,迟国泰.基于熵权法的科学技术评价模型及其实证研究[J].管理学报,2010,7(01):34-42.
[6]黄小艳.运筹学和数学综合评价方法研究综述[J].企业改革与管理,2015(09):145-146.
[7]Yoon K, Hwang C L. TOPSIS (technique for order preference by similarity to ideal solution)–a multiple attribute decision making, w: Multiple attribute decision making–methods and applications, a state-of-the-at survey[J]. Berlin: Springer Verlag, 1981.
[8]胡永宏.对TOPSIS法用于综合评价的改进[J].数学的实践与认识,2002(04):572-575.
[9]夏勇其,吴祈宗.一种混合型多属性决策问题的TOPSIS方法[J].系统工程学报,2004(06):630-634.
[10]周亚. 多属性决策中的TOPSIS法研究[D].武汉理工大学,2009.
[11]樊宏,吉华萍,杜宪明,尤华,陆慧.应用综合指数法及秩和比法综合评价某市2008年~2010年的医疗服务质量[J].卫生软科学,2012,26(03):201-203.
[12]虞晓芬,傅玳.多指标综合评价方法综述[J].统计与决策,2004(11):119-121.
[13]何晓群. 多元统计分析(第四版)[M]. 中国人民大学出版社, 2015.
注:部分文字、图片来自网络,如涉及侵权,请及时与我们联系,我们会在第一时间删除或处理侵权内容,电话:4006770986。
