朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法。在机器学习中,朴素贝叶斯和其他大多数的分类算法都不同,比如决策树、KNN、支持向量机等,他们都是判别方法,直接学习出特征输出Y和特征输出X之间的关系,Y=f(X)或者P(Y|X)。但朴素贝叶斯是生成方法,是直接找出特征输出Y和特征X的联合分布P(X,Y),然后用P(Y|X)=P(X,Y)/P(X)得出。
0 朴素贝叶斯算法的主要学习内容
1)朴素贝叶斯法的学习与分类
2)朴素贝叶斯法的参数估计
1朴素贝叶斯算法学习的前期准备


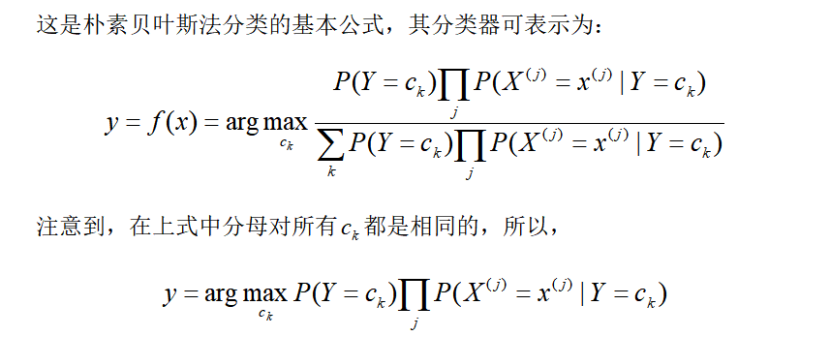
1.1后验概率最大化的含义[1]
朴素贝叶斯法将实例分到后验概率最大的类中,这等价于期望风险最小化,假设选择0-1损失函数:

这样一来,根据期望风险最小化准则就得到了后验概率最大准则:
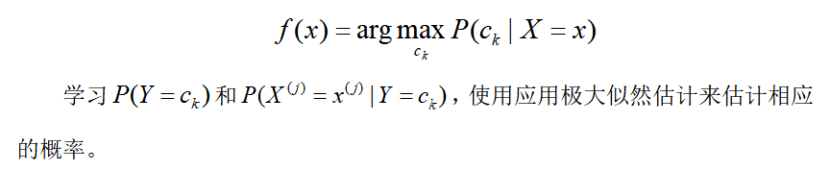
1.2极大似然估计[1]

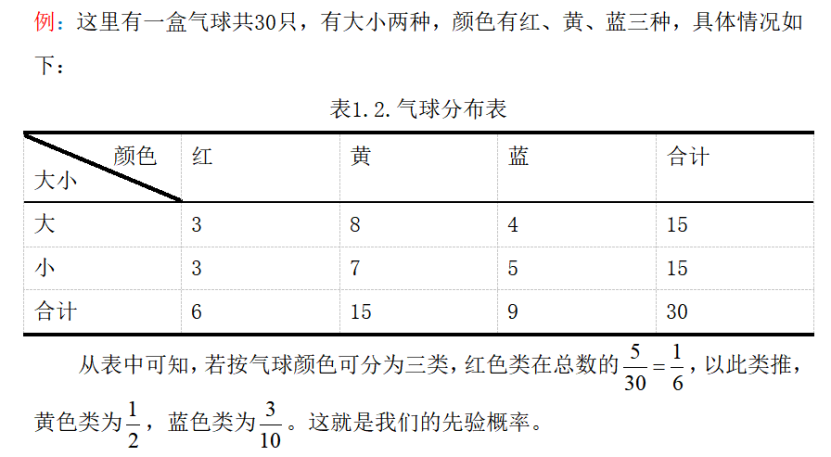


1.3 学习与分类算法




2 贝叶斯估计
使用极大似然估计可能会出现所要估计的概率值为0的情况,这时会影响到后验概率的计算结果,使分类产生偏差,解决这一问题的方法是采用贝叶斯估计,它与朴素贝叶斯估计有什么不同呢




3朴素贝叶斯算法总结
朴素贝叶斯是典型的生成学习方法,是直接找出特征输出Y和特征X的联合分布P(X,Y),然后用P(Y|X)=P(X,Y)/P(X)得出,对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就判定该待分项属于哪个类。
3.1朴素贝叶斯的主要优点:
1)朴素贝叶斯模型有稳定的分类效率
2)朴素贝叶斯很直观,计算量也不大
3)对小样本数据表现很好,能处理多分类任务。
4)对缺失数据不敏感,算法也比较简单,常用于文本分类。
3.2朴素贝叶斯的主要缺点:
1)理论上,朴素贝叶斯模型与其他分类方法相比具有最小的误差率。但是实际上并非总是如此,这是因为朴素贝叶斯模型给定输出类别的情况下,假设属性之间相互独立,这个假设在实际应用中往往是不成立的,在属性个数比较多或者属性之间相关性较大时,分类效果不好。而在属性相关性较小时,朴素贝叶斯性能最为良好
2)需要知道先验概率,且先验概率很多时候取决于假设,假设的模型可以有很多种,因此在某些时候会由于假设的先验模型的原因导致预测效果不佳。
3)由于我们是通过先验和数据来决定后验的概率从而决定分类,所以分类决策存在一定的错误率。
4)对输入数据的表达形式很敏感。
4 朴素贝叶斯算法的应用
1)垃圾邮件分类
2)病症判断,即病人分类
3)检测某社区平台不真实账号
4)新闻分类
参考文献
[1]李航,《统计学习方法》
[2]https://www.cnblogs.com/lliuye/p/9178090.html
[3]http://bbs.elecfans.com/jishu_1659159_1_1.html
[4] https://www.cnblogs.com/leoo2sk/archive/2010/09/17/naive-bayesian-classifier.html
注:部分文字、图片来自网络,如涉及侵权,请及时与我们联系,我们会在第一时间删除或处理侵权内容,电话:4006770986。
