支持向量机(SVM)是一种二分类模型,是在统计学习理论基础上发展起来的一种数据挖掘方法,1992年提出。它的基本模型是定义在特征空间上的间隔最大的线性分类器,间隔最大使它有别于感知机。在解决小样本、非线性、高维度的分类问题上有很大的优势[1]。
支持向量机还包含核技巧,这使它成为实质上的非线性分类器,支持向量机的学习策略是间隔最大化,可形式化为一个求解凸二次规划的问题,也等价于正则化的合页损失函数的最小化问题。简单说,支持向量机的学习算法是求解凸二次规划的最优化算法[2]。
0 支持向量机主要学习内容
(1) 线性可分支持向量机与硬间隔最大化:当训练数据完全线性可分时可用硬间隔支持向量机;间隔的不同表示法;如何找到最大间隔分离超平面。
(2) 学习对偶算法
(3) 支持向量:区别线性可分时(硬间隔)和线性不完全可分时(软间隔),支持向量的不同之处。
(4) 线性支持向量机与软间隔最大化
(5) 非线性支持向量机与核函数
1线性可分支持向量机与硬间隔最大化
1.1线性可分支持向量机
假设支持向量分类对象包含n个观测样本,每个观测有p个输入(特征)变量和一个输出变量。

注:简单点讲就是,每行是一个观测样本,有多少行就有多少个训练样本,这里有n行,即n个训练样本;前p列为变量个数,即特征个数,最后一列为输出变量,也就是类别标记。综合起来,可将n个观测样本看成p维特征空间的n个点,然后点的不同形状或颜色可代表不同类别取值。
支持向量是如何将训练样本进行分类的呢?
如图,以二维特征空间为例,我们找到了一条线将正方形与圆形分开。图中红色方块代表的观测,输出变量y=+1,黄色圆点代表的观测,输出变量为y=-1。绿色三角形对应的观测是未知输出变量的新观测,是想通过这个模型得出它们的输出变量类别标记。
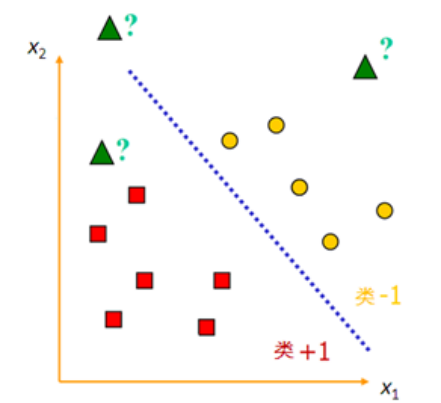
那如果在三维、四维空间呢,还能用一条直线分隔吗?答案是不能的。例如一块豆腐,从空间几何上说,它是属于三维立体几何,将它一刀切后,分成了两块,切痕是一个平面。四维空间呢,切痕其实也是一个平面,但与三维的有所不同,故我们将特征空间中将训练样本分类的工具统称为超平面。
我们使用支持向量机分类时,其主要目标是在特征空间中找到一个分离超平面,能将实例分到不同的类。

是不是感觉和感知机算法原理差不多?
如果你感觉是有点共同的话,那你在学习支持向量机时会轻松一些。一般,当训练数据完全线性可分时,感知机利用误分类最小的策略,求得分离超平面,这样的超平面会存在无穷多个。我们该选择哪一个更好呢?感知机它也不知道,这也是感知机的一个缺点,解不唯一性。相比之下,线性完全可分的支持向量机可利用间隔最大化求出最优分离超平面,这样的超平面是唯一确定的,成功解决了感知机解不唯一性的缺点。
1.2 线性完全可分支持向量机的定义

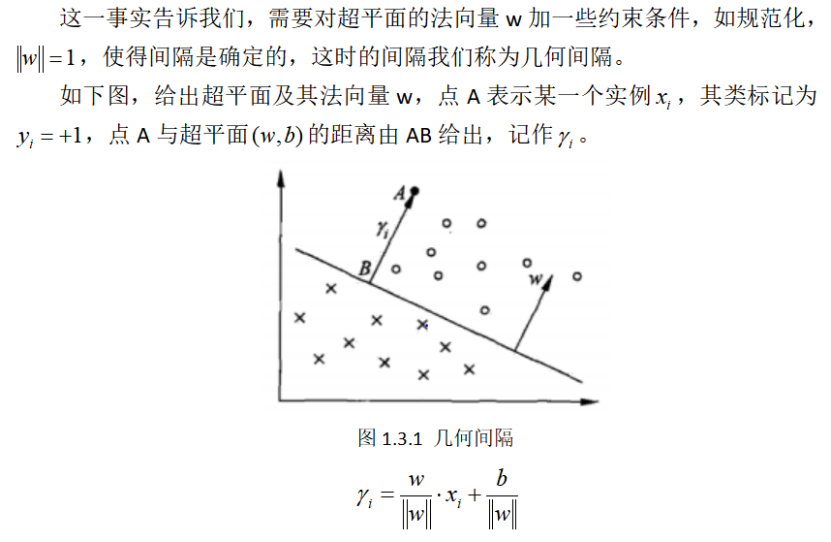
1.3函数间隔和几何间隔[2]

函数间隔可以表示分类预测的正确性及确定度,但是选择分离超平面时,只有函数间隔是不够的,因为只要成比例地改变参数w和b,例如将它们改为2w和2b,超平面并没有改变,但函数间隔却变为原来的2倍。



间隔最大化
间隔最大化得直观解释是:对训练数据集找到几何间隔最大的超平面,也就是说以充分大的确信度对训练数据集进行分类,不仅将正负实例点分开,而且对最难分的实例点(离超平面最近的点)也能以足够大的确信度将它们分开,这样的超平面应该对未知的新实例有很好的预测能力。
最大间隔分离超平面
下面考虑如何求得一个几何间隔最大的分离超平面,即最大间隔分离超平面,具体地,这个问题可以表示为下面的约束最优化问题:




支持向量和间隔边界
在线性可分情况下,训练数据集的样本点中与分离超平面距离最近的样本点的实例成为支持向量,支持向量是使约束条件成立的点,即:

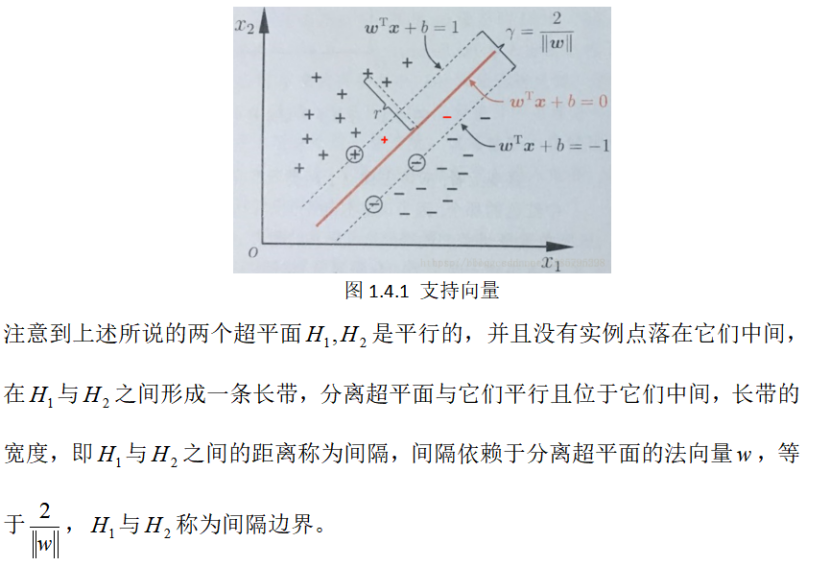
注意:在决定分离超平面时,只有支持向量起作用,而其他实例点并不起作用。通俗地说:移动支持向量将改变我们所要求得超平面,但移动不是支持向量的实例点(没有在间隔边界上的点),甚至去掉这些点,我们的超平面也不会改变。这种依靠支持向量来决定分离超平面的模型就称为支持向量机。支持向量机的个数一般很少,所以该模型的训练掌握在少数实例点上。
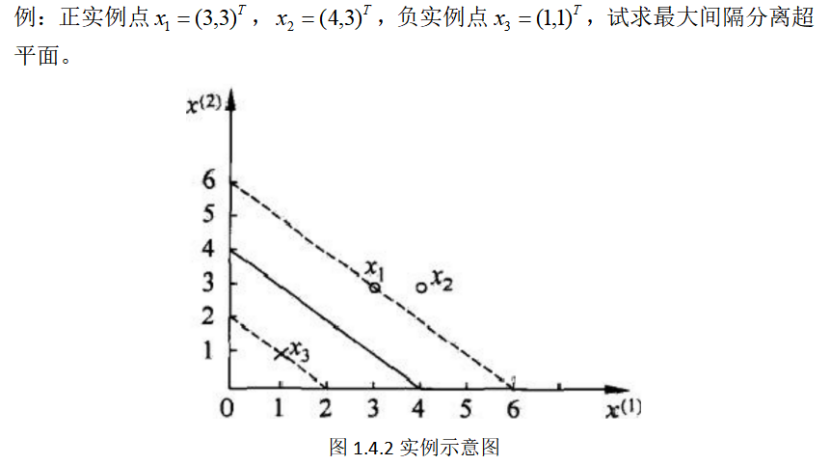

1.5 学习的对偶算法[2]
支持向量机学到这里,大家有没有发现它的原理与感知机有很多相通的地方,感知机有对偶算法,那支持向量机是否也有呢?答案是肯定的,那它们使用得对偶算法相同吗?为什么要使用对偶算法呢?
下面我列几条对偶算法的优点:第一,对偶问题往往容易求解;二,可引入核函数,推广并易于解决非线性分类问题。
支持向量机构建对偶算法的步骤:
首先构建拉格朗日函数,为此,对每一个不等式约束

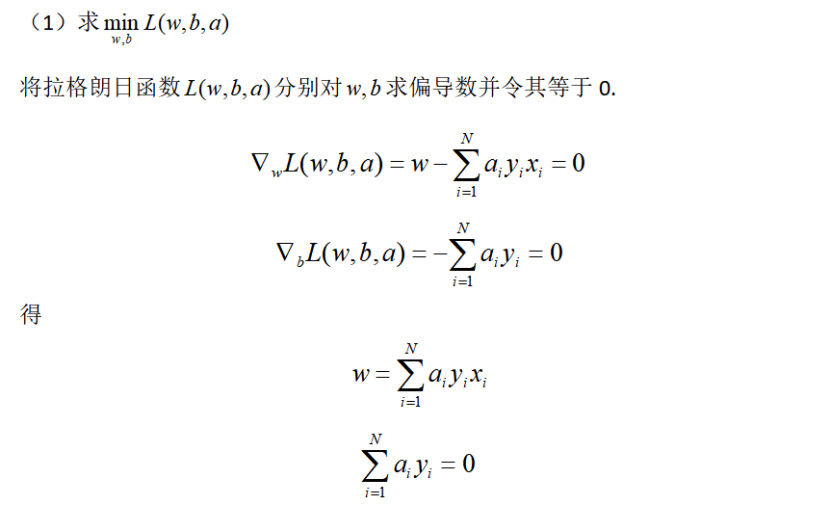


下面解释一下:原始最优化问题和对偶最优化问题解的关系,先看一下李航老师在《统计学习方法》中所写的定理如下[2]:





我们的支持向量机满足KKT条件,所以对偶问题的解就是原始问题的解。即:



1.6总结一下:线性可分支持向量机学习算法[2]

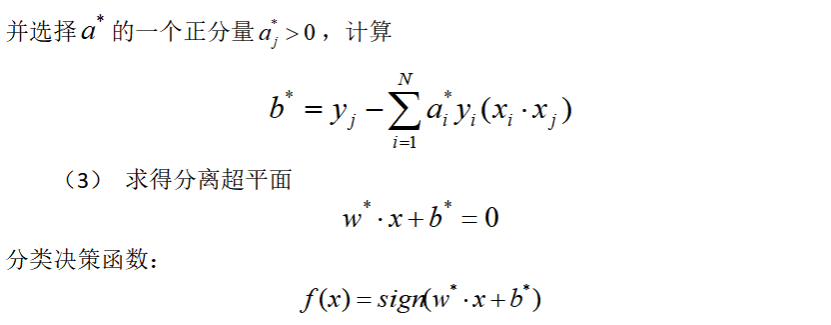


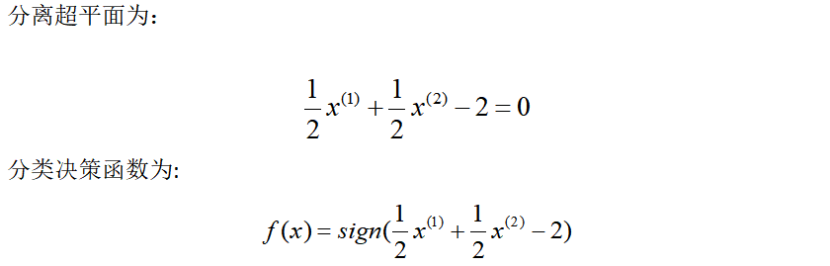
上述算法内容是建立在线性可分的条件下,但现实中,训练数据集往往是线性不可分的,即在样本中出现噪声或异常点,此时,需要更一般的学习算法来进行分类任务。
2 线性支持向量机与软间隔最大化[2]
在线性不可分下,线性可分问题的支持向量机方法,已不适用。因此上述方法中的约束条件并不能成立,怎么才能将它扩展到线性不可分问题上去呢?可以通过修改硬间隔为软间隔来实现。那软间隔又是怎么定义的呢?我们一步一步来解答。
通常情况下,训练数据中总有一些不合人意的特异点,有人说,那我们可以将它们去掉啊!可在训练样本较少或者这种特异点较多时,去掉特异点会让我们的训练失去真实性,所以这种办法时行不通的。故有人提出了软间隔。


2.1线性支持向量机的学习的对偶算法[2]



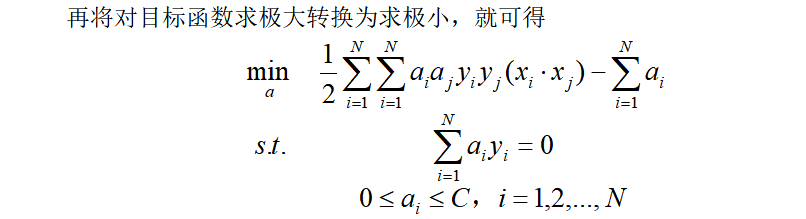

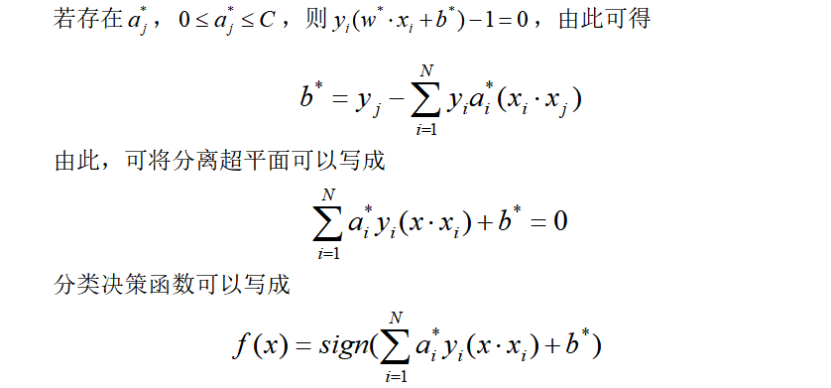
2.2 总结一下线性支持向量机学习算法[2]


2.3软间隔的支持向量
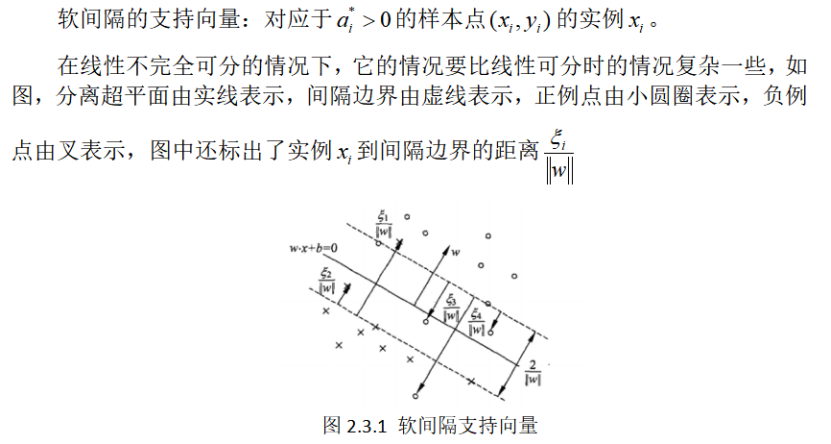

对于线性分类问题,线性分类支持向量机式一种非常有效的方法,但是,有时的分类问题是非线性的,这时可以使用非线性支持向量机,其主要特点是利用核函数技巧。特征空间进行非线性转换,将低维特征空间中的线性不可分通过非线性转换,转为在高维中的线性可分问题。
2.5核函数[2]




2.6非线性支持向量机学习算法[2]

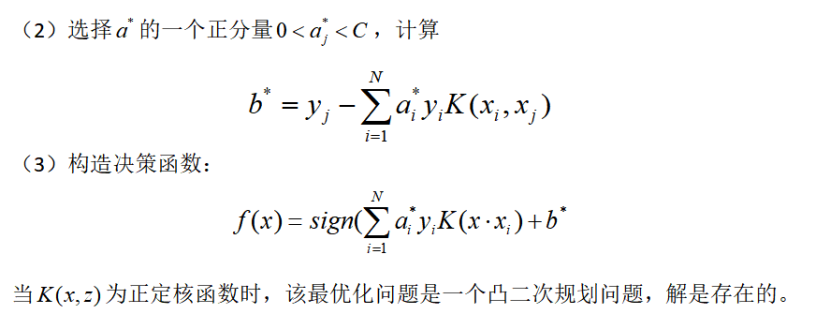
3支持向量机算法总结
SVM是一种有坚实理论基础的分类学习方法。它基本上不涉及概率测度及大数定律等,也简化了通常的分类和回归等问题。它最终的决策函数只由少数的支持向量所确定,计算的复杂性取决于支持向量的数目,而不是样本空间的维数,这在某种意义上避免了“维数灾难”。
3.1支持向量机的优点:
1.SVM是一种适用小样本学习方法。计算的复杂性取决于支持向量的数目,而不是样本空间的维数,这在某种意义上避免了“维数灾难”。
2. 少数支持向量决定了最终结果,对异常值不敏感, 这不但可以帮助我们抓住关键样本、“剔除”大量冗余样本,而且注定了该方法不但算法简单,而且具有较好的“鲁棒性”
3. SVM学习问题可以表示为凸优化问题,因此可以利用已知的有效算法发现目标函数的全局最小值,
4.有优秀的泛化能力。
3.2 支持向量机的缺点:
1.对大规模训练样本难以实施:SVM的空间消耗主要是存储训练样本和核矩阵,当训练数目很大时,该矩阵的存储和计算将耗费大量的机器内存和运算时间。
2.解决多分类问题困难:经典的支持向量机算法只给出了二类分类的算法,而在实际应用中,一般要解决多类的分类问题。可以通过多个二类支持向量机的组合来解决。主要有一对多组合模式、一对一组合模式和SVM决策树;再就是通过构造多个分类器的组合来解决。主要原理是克服SVM固有的缺点,结合其他算法的优势,解决多类问题的分类精度。
3.对参数和核函数选择敏感 支持向量机性能的优劣主要取决于核函数的选取,所以对于一个实际问题而言,如何根据实际的数据模型选择合适的核函数从而构造SVM算法。目前比较成熟的核函数及其参数的选择都是人为的,根据经验来选取的,带有一定的随意性。
4支持向量机算法运用场景
1、垃圾邮件分类
2、根据分析顾客几个月的消费行为,来预测未来一个月天猫订单成交数。
3、图像分类
4、信用评分
参考文献
[1]薛薇,《R语言数据挖掘》
[2]李航,《统计学习方法》
[3]http://blog.sina.com.cn/s/blog_6d979ba00100oel2.html
[4]https://blog.csdn.net/csqazwsxedc/article/details/52230092
[5]http://www.doc88.com/p-8405508144971.html
[6]http://www.doc88.com/p-077807520284.html
[7]https://www.taodocs.com/p-32101770.html
注:部分文字、图片来自网络,如涉及侵权,请及时与我们联系,我们会在第一时间删除或处理侵权内容,电话:4006770986。
